线性表
顺序表
顺序表初始化
定义数据表
-
顺序表申请的存储容量;
-
顺序表的长度,也就是表中存储数据元素的个数;
typedef struct Table{ |
注意:head 是我们声明的一个未初始化的动态数组,不要只把它看做是普通的指针。
数据表的初始化
-
给 head 动态数据申请足够大小的物理空间;
-
给 size 和 length 赋初值;
|
顺序表初始化的过程被封装到了一个函数中,此函数返回值是一个已经初始化完成的顺序表。这样做的好处是增加了代码的可用性,也更加美观。
顺序表的基本操作
顺序表插入元素
向已有顺序表中插入数据元素,根据插入位置的不同,可分为以下 3 种情况:
-
插入到顺序表的表头;
-
在表的中间位置插入元素;
-
尾随顺序表中已有元素,作为顺序表中的最后一个元素;
插入的步骤:
-
将要插入位置元素以及后续的元素整体向后移动一个位置;
-
将元素放到腾出来的位置上;
顺序表插入数据元素的 C 语言实现代码如下:
//插入函数,其中,elem为插入的元素,add为插入到顺序表的位置 |
注意,动态数组额外申请更多物理空间使用的是 realloc 函数。并且,在实现后续元素整体后移的过程,目标位置其实是有数据的,还是 3,只是下一步新插入元素时会把旧元素直接覆盖。
顺序表删除元素
删除的步骤:
找到目标元素,并将其后续所有元素整体前移 1 个位置即可。
顺序表删除元素的 C 语言实现代码为:
table delTable(table t,int add){ |
顺序表查找元素
方法:顺序查找法
//查找函数,其中,elem表示要查找的数据元素的值 |
顺序表更改元素
顺序表更改元素的步骤是:
-
找到目标元素;
-
直接修改该元素的值;
顺序表更改元素的 C 语言实现代码为:
//更改函数,其中,elem为要更改的元素,newElem为新的数据元素 |
链表
与顺序表不同,链表不限制数据的物理存储状态,换句话说,使用链表存储的数据元素,其物理存储位置是随机的。
链式存储结构:数据元素随机存储,并通过指针表示数据之间逻辑关系的存储结构
链表的节点
| data | point |
|---|---|
| 数据域 | 指针域 |
-
数据元素本身,其所在的区域称为数据域;
-
指向直接后继元素的指针,所在的区域称为指针域;
链表中每个节点的具体实现,需要使用 C 语言中的结构体,具体实现代码为:
typedef struct Link{ |
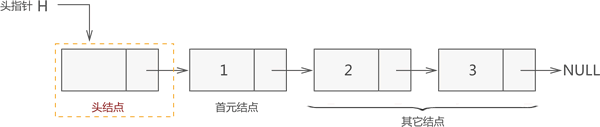
头节点,头指针和首元节点
一个完整的链表需要由以下几部分构成:
1.头指针:一个普通的指针,它的特点是永远指向链表第一个节点的位置。很明显,头指针用于指明链表的位置,便于后期找到链表并使用表中的数据;
- 节点:链表中的节点又细分为头节点、首元节点和其他节点:
-
头节点:其实就是一个不存任何数据的空节点,通常作为链表的第一个节点。对于链表来说,头节点不是必须的,它的作用只是为了方便解决某些实际问题;
-
首元节点:由于头节点(也就是空节点)的缘故,链表中称第一个存有数据的节点为首元节点。首元节点只是对链表中第一个存有数据节点的一个称谓,没有实际意义;
-
其他节点:链表中其他的节点;
## 链表的创建(初始化)
创建链表的步骤是:
-
声明一个头指针(如果有必要,可以声明一个头节点);
-
创建多个存储数据的节点,在创建的过程中,要随时与其前驱节点建立逻辑关系;
例如
创建一个存储 {1,2,3,4} 且无头节点的链表,C 语言实现代码如下:
link * initLink(){ |
创建一个存储 {1,2,3,4} 且含头节点的链表,则 C 语言实现代码为:
link * initLink(){ |
链表的基本操作
链表插入元素
向链表中增添元素,根据添加位置不同,可分为以下 3 种情况:
-
插入到链表的头部(头节点之后),作为首元节点;
-
插入到链表中间的某个位置;
-
插入到链表的最末端,作为链表中最后一个数据元素;
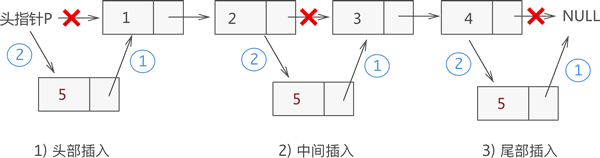
链表插入元素的步骤:
-
将新结点的 next 指针指向插入位置后的结点;
-
将插入位置前结点的 next 指针指向插入结点;
注意:链表插入元素的操作必须是先步骤 1,再步骤 2;反之,若先执行步骤 2,除非再添加一个指针,作为插入位置后续链表的头指针,否则会导致插入位置后的这部分链表丢失,无法再实现步骤 1。
实现链表插入元素的操作:
//p为原链表,elem表示新数据元素,add表示新元素要插入的位置 |
链表删除元素
链表删除元素的步骤:
- 将结点从链表中摘下来;
2.手动释放掉结点,回收被结点占用的存储空间;
链表删除元素的的操作:
link * delElem(link * p, int add) { |
链表查找元素
步骤:从表头依次遍历表中节点,用被查找元素与各节点数据域中存储的数据元素进行比对,直至比对成功或遍历至链表最末端的 NULL(比对失败的标志)。
链表中查找特定数据元素的操作:
//p为原链表,elem表示被查找元素、 |
注意,遍历有头节点的链表时,需避免头节点对测试数据的影响,因此在遍历链表时,建立使用上面代码中的遍历方法,直接越过头节点对链表进行有效遍历。
链表更新元素
步骤:通过遍历找到存储此元素的节点,对节点中的数据域做更改操作即可。
链表中更新数据元素的操作
//更新函数,其中,add 表示更改结点在链表中的位置,newElem 为新的数据域的值 |
静态链表
静态链表:兼顾了顺序表和链表的优点于一身,可以看做是顺序表和链表的升级版。
使用静态链表存储数据,数据全部存储在数组中(和顺序表一样),但存储位置是随机的,数据之间"一对一"的逻辑关系通过一个整形变量(称为"游标",和指针功能类似)维持(和链表类似)。
静态链表中的节点
静态链表存储数据元素也需要自定义数据类型,至少需要包含以下 2 部分信息:
- 数据域:用于存储数据元素的值;
- 其实就是数组下标,表示直接后继元素所在数组中的位置;
静态链表中节点的构成用 C 语言实现为:
typedef struct { |
备用链表
备用链表:静态链表中,除了数据本身通过游标组成的链表外,还需要有一条连接各个空闲位置的链表,称为备用链表。
备用链表的作用是回收数组中未使用或之前使用过(目前未使用)的存储空间,留待后期使用。也就是说,静态链表使用数组申请的物理空间中,存有两个链表,一条连接数据,另一条连接数组中未使用的空间。
通常,备用链表的表头位于数组下标为 0(a[0]) 的位置,而数据链表的表头位于数组下标为 1(a[1])的位置。
静态链表中设置备用链表的好处是,可以清楚地知道数组中是否有空闲位置,以便数据链表添加新数据时使用。比如,若静态链表中数组下标为 0 的位置上存有数据,则证明数组已满。
静态链表的创建